最近 AI 很紅,紅到在 YouTube, Podcast 上三不五時就來個 AI 主題。為什麼 AI 這麼迷人?因為 AI 可以透過學習,模仿人類,如演講、繪圖、寫歌、…。如果模仿的準確度高的話,就可能取代人類😱🥲 – 人工作會累容易出錯,機器幾乎不會。
AI 浪潮來襲,雖然我只是個門外漢,但多少也想分杯羹😆看見 YouTube 上有些專家在分享如何”行雲流水”般的用 AI 輾壓式的解決一些問題,如寫 AI 程式玩遊戲,結果 AI 練到遊戲關卡一個個被完全輾壓😱
而我感覺到這”行雲流水的操作”就很有意思了,它似乎透露要寫這麼一個 AI 程式,現有的網路資源比以前容易取得、達成目的!因此我覺得我應該也能在幾天的時間內寫出一支 AI 程式,為自己開闢能設計 AI 以解決問題的能力。
我參考的一部 YouTube 影片教學是寫強化學習 (reinforcement learning, RL) AI 玩遊戲。雖然影片略過一些細節演算法與實作,但大致上是利用 ChatGPT 生成一支 Python pygame 的遊戲原始碼,再用 ChatGPT 生成一支 Python OpenAI gym 的 RL 樣版程式碼,再將兩者接起了以達成 AI 自我學習玩遊戲的訓練程式。
我也依樣畫葫蘆先用 ChatGPT 生成一支 Python 貪食蛇遊戲,不過有些許 bugs,稍微改一下就能用。接著用 ChatGPT 生成 Q-learning RL 程式碼,但我以前沒學過 OpenAI gym 的框架,不知道程式碼要怎麼改,因此只好看 gym 的文件、以及一些 YouTube 影片學了一下,尤其以最簡單的 Frozen Lake 遊戲為對象,研究如何使用 gym。
(這一段較學術研究)經過一天的研究,我終於對 RL 有些概念了:RL 很適合處理一些具有分數 (reward) 回饋的被控系統 (environment, env)。例如:遊戲 (env) 往往有分數 (score / reward),我們就可以設計一個 RL agent 控制遊戲,並從遊戲的分數學習每一次的控制 (action) 如何才能達到最高分。RL agent 可用不同 AI 演算法去寫,我用的是 Q-learning,它的好處是”通用性”,不限特定 env 才能使用。Q-learning 有一個狀態表 (Q table),它記錄著 env 某一狀態 (state) 下,執行 agent 選擇的某個 action 會有多好 reward 的值 (Q value)。而 Q-learning 每次迭代 (episode),agent 選了一個 action 輸入 env,然後 env 運算完會輸出 reward 及 new state,agent 再依這兩個資訊去更新 Q table 此 state-action 組合為索引的 Q value。Q table 就是要經由大量的訓練才可達到適用此 env 的 AI,這是一個最佳化 (optimization) 問題。如果我們在一開始訓練 Q table 時,不加入一些隨機性,很可能會依 Q table 初始值找到很差的次佳解!因此 agent 在初始訓練,我們可以多用一些隨機 action 以探索 (exploration) 較好的解。而訓練一段時間後,Q table 已經逼近一個最佳解時,反而要降低探索的機率,使 reward 能漸漸收斂,不再大幅度上下振盪,所以要作 exploration decay 演算法!而 exploration decay 的調校也很有意思,不是一套公式複製、貼上就萬用,我發現若能估計大約多少 episodes 能收斂,再調 exploration decay 公式適時 decay 夠低,才能快速收斂。再來談 state 是什麼。它是一組參數,與 action 搭配後與 env 的 reward 有高度相關性,所以要盡量找出相關的參數作為 state,訓練方向才會正確。
(這一段也較學術研究) 我為了快速完成我的第一支 RL 程式並呈現學習效果,將貪食蛇遊戲簡化成蛇只有撞牆才會遊戲結束並且輸出很負的 reward,而每成功走一步就得 1 個 reward。state 參數是”蛇頭位置”及”行走方向”,action 則是控制行走方向(左、下、右、上)。其實原本 state 我沒加上”行走方向”,訓練後發現 AI 很笨蛇一直撞牆,後來 debug 才發現 Q 值異常、蛇的行走方向會影響 action 的有效性!例如蛇頭行走方向向左走到左牆時,此時控制蛇往右是無效控制,因此下一步就會撞牆,所以”行走方向”也是影響 reward 的重要參數。後來將行走方向加入 state 參數才解決問題🙂最後還是聲明一下,以上只是 AI 業餘的我對 RL 的一些理解與記錄,部分缺乏實證,僅供參考。
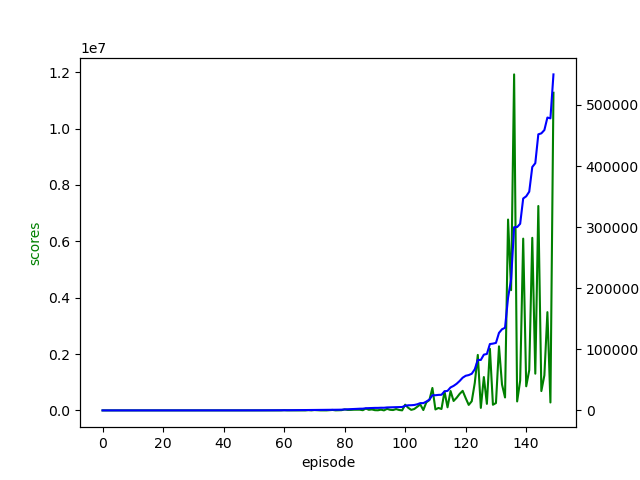
我這次嘗試還滿意的,覺得自己學到一些設計 AI 處理問題的知識、能力,希望哪天可以用來處理一些更實際的問題。以下附上一張訓練結果圖與訓練影片,平均得分有隨著訓練增加。